
Author: Serge Stefoglo / Source: Moz If you work on an enterprise site — particularly in e-commerce or listings (such as a job board site

If you work on an enterprise site — particularly in e-commerce or listings (such as a job board site) — you probably use some sort of faceted navigation structure. Why wouldn’t you? It helps users filter down to their desired set of results fairly painlessly.
While helpful to users, it’s no secret that faceted navigation can be a nightmare for SEO. At Distilled, it’s not uncommon for us to get a client that has tens of millions of URLs that are live and indexable when they shouldn’t be. More often than not, this is due to their faceted nav setup.
There are a number of great posts out there that discuss what faceted navigation is and why it can be a problem for search engines, so I won’t go into much detail on this. A great place to start is this post from 2011.
What I want to focus on instead is narrowing this problem down to a simple question, and then provide the possible solutions to that question. The question we need to answer is, “What options do we have to decide what Google crawls/indexes, and what are their pros/cons?”
Brief overview of faceted navigation
As a quick refresher, we can define faceted navigation as any way to filter and/or sort results on a webpage by specific attributes that aren’t necessarily related. For example, the color, processor type, and screen resolution of a laptop. Here is an example:
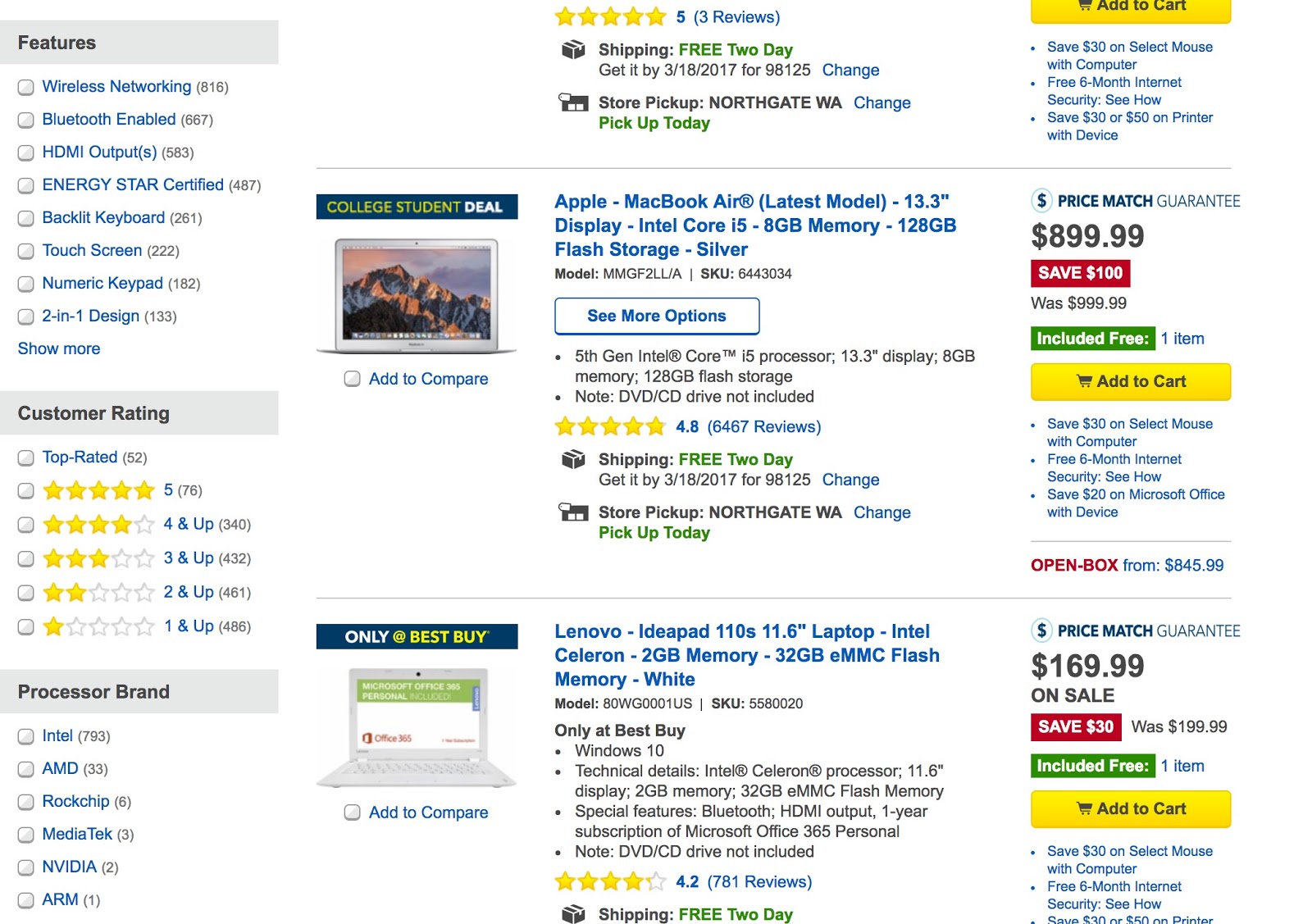
Because every possible combination of facets is typically (at least one) unique URL, faceted navigation can create a few problems for SEO:
- It creates a lot of duplicate content, which is bad for various reasons.
- It eats up valuable crawl budget and can send Google incorrect signals.
- It dilutes link equity and passes equity to pages that we don’t even want indexed.
But first… some quick examples
It’s worth taking a few minutes and looking at some examples of faceted navigation that are probably hurting SEO. These are simple examples that illustrate how faceted navigation can (and usually does) become an issue.
Macy’s
First up, we have Macy’s. I’ve done a simple site:search for the domain and added “black dresses” as a keyword to see what would appear. At the time of writing this post, Macy’s has 1,991 products that fit under “black dresses” — so why are over 12,000 pages indexed for this keyword? The answer could have something to do with how their faceted navigation is set up. As SEOs, we can remedy this.

Let’s take Home Depot as another example. Again, doing a simple site:search we find 8,930 pages on left-hand/inswing front exterior doors. Is there a reason to have that many pages in the index targeting similar products? Probably not. The good news is this can be fixed with the proper combinations of tags (which we’ll explore below).

I’ll leave the examples at that. You can go on most large-scale e-commerce websites and find issues with their navigation. The points is, many large websites that use faceted navigation could be doing better for SEO purposes.
Faceted navigation solutions
When deciding a faceted navigation solution, you will have to decide what you want in the index, what can go, and then how to make that happen. Let’s take a look at what the options are.
“Noindex, follow”
Probably the first solution that comes to mind would be using noindex tags. A noindex tag is used for the sole purpose of letting bots know to not include a specific page in the index. So, if we just wanted to remove pages from the index, this solution would make a lot of sense.
The issue here is that while you can reduce the amount of duplicate content that’s in the index, you will still be wasting crawl budget on pages. Also, these pages are receiving link equity, which is a waste (since it doesn’t benefit any indexed page).
Example: If we wanted to include our page for “black dresses” in the index, but we didn’t want to have “black dresses under $100” in the index, adding a noindex tag to the latter would exclude it. However, bots would still be coming to the page (which wastes crawl budget), and the page(s) would still be receiving link equity (which would be a waste).
Canonicalization
Many sites approach this issue by using canonical tags. With a canonical tag, you can let Google know that in a collection of similar pages, you have a preferred version that should get credit. Since canonical tags were designed as a solution to duplicate content, it would seem that this is a reasonable solution. Additionally, link equity will be consolidated to the canonical page (the one you deem most important).
However, Google will still be wasting crawl budget on pages.
Example: /black-dresses?under-100/ would have the canonical URL set to /black-dresses/. In this instance, Google would give the canonical page the authority and link equity. Additionally, Google wouldn’t see the “under $100” page as a duplicate of the canonical version.
Disallow via robots.txt
Disallowing sections of the site (such as certain parameters) could be a great solution. It’s quick, easy, and is customizable. But, it does come with…
COMMENTS