
Source: Neil Patel Everyone loves “hacks.” I’m no exception––I love finding ways to make my life better and easier. That’s why the technique I’m go

Everyone loves “hacks.”
I’m no exception––I love finding ways to make my life better and easier.
That’s why the technique I’m going to tell you about today is one of my absolute favorites. It’s a legitimate SEO hack that you can start using right away.
It’s a way to increase your SEO by taking advantage of a natural part of every website that rarely gets talked about. It’s not difficult to implement either.
It’s the robots.txt file (also called the robots exclusion protocol or standard).
This teeny tiny text file is part of every website on the Internet, but most people don’t even know about it.
It’s designed to work with search engines, but surprisingly, it’s a source of SEO juice just waiting to be unlocked.
I’ve seen client after client bend over backward trying to enhance their SEO. When I tell them that they can edit a little text file, they almost don’t believe me.
However, there are many methods of enhancing SEO that aren’t difficult or time-consuming, and this is one of them.
You don’t need to have any technical experience to leverage the power of robots.txt. If you can find the source code for your website, you can use this.
So when you’re ready, follow along with me, and I’ll show you exactly how to change up your robots.txt file so that search engines will love it.
Why the robots.txt file is important
First, let’s take a look at why the robots.txt file matters in the first place.
The robots.txt file, also known as the robots exclusion protocol or standard, is a text file that tells web robots (most often search engines) which pages on your site to crawl.
It also tells web robots which pages not to crawl.
Let’s say a search engine is about to visit a site. Before it visits the target page, it will check the robots.txt for instructions.
There are different types of robots.txt files, so let’s look at a few different examples of what they look like.
Let’s say the search engine finds this example robots.txt file:

This is the basic skeleton of a robots.txt file.
The asterisk after “user-agent” means that the robots.txt file applies to all web robots that visit the site.
The slash after “Disallow” tells the robot to not visit any pages on the site.
You might be wondering why anyone would want to stop web robots from visiting their site.
After all, one of the major goals of SEO is to get search engines to crawl your site easily so they increase your ranking.
This is where the secret to this SEO hack comes in.

You probably have a lot of pages on your site, right? Even if you don’t think you do, go check. You might be surprised.
If a search engine crawls your site, it will crawl every single one of your pages.
And if you have a lot of pages, it will take the search engine bot a while to crawl them, which can have negative effects on your ranking.
That’s because Googlebot (Google’s search engine bot) has a “crawl budget.”
This breaks down into two parts. The first is crawl rate limit. Here’s how Google explains that:

The second part is crawl demand:

Basically, crawl budget is “the number of URLs Googlebot can and wants to crawl.”
You want to help Googlebot spend its crawl budget for your site in the best way possible. In other words, it should be crawling your most valuable pages.
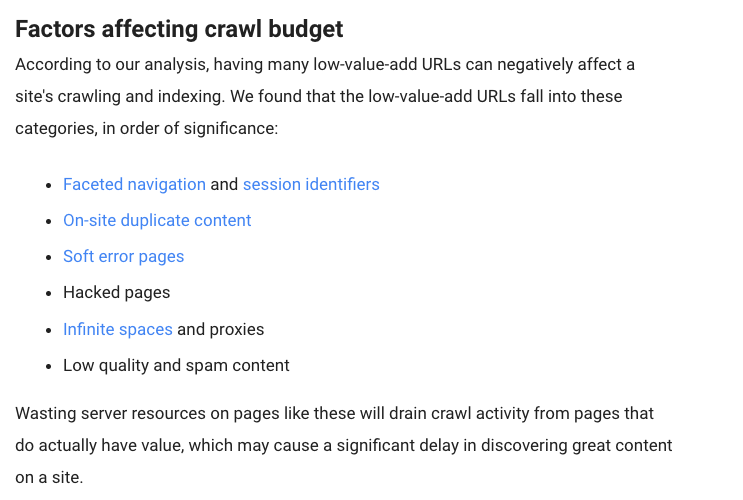
There are certain factors that will, according to Google, “negatively affect a site’s crawling and indexing.”
Here are those factors:
So let’s come back to robots.txt.
If you create the right robots.txt page, you can tell search engine bots (and especially Googlebot) to avoid certain pages.
Think about the implications. If you tell search engine bots to only crawl your most useful content, the bots will crawl and index your site based on that content alone.
“You don’t want your server to be overwhelmed by Google’s crawler or to waste crawl budget crawling unimportant or similar pages on your site.”
By using your robots.txt the right way, you can tell search engine bots to spend their crawl budgets wisely. And that’s what makes the robots.txt file so useful in an SEO context.
Intrigued by the power of robots.txt? You should be! Let’s talk about how to find and use it.
You should be! Let’s talk about how to find and use it.
Finding your robots.txt file
If you just want a quick look at your robots.txt file, there’s a super easy way to view it.
In fact, this method will work for any site. So you can peek on other sites’ files and see what they’re doing.
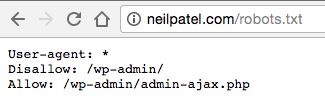
All you have to do it type the basic URL of the site into your browser’s search bar (e.g., neilpatel.com, quicksprout.com, etc.). Then add /robots.txt onto the end.
One of three situations will happen:
1) You’ll find a robots.txt file.
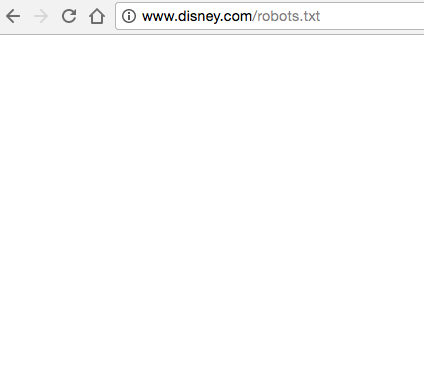
2) You’ll find an empty file.
For example, Disney seems to lack a robots.txt file:
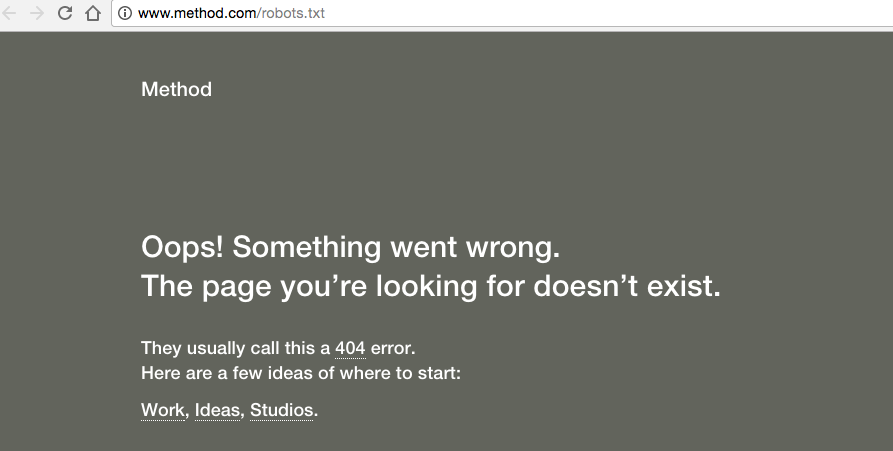
3) You’ll get a 404.
Method returns a 404 for robots.txt:
Take a second and view your own site’s robots.txt file.
If you find an empty file or a 404, you’ll want to fix that.
If you do find a valid file, it’s probably set to default settings that were created when you made your site.
I especially like this method for looking at other sites’ robots.txt files. Once you learn the ins and outs of robots.txt, this can be a valuable exercise.
Now let’s look at actually changing your robots.txt file.
Finding your robots.txt file

Your next steps are all going to depend on whether or not you have a robots.txt file. (Check…
COMMENTS